Voice-to-Video: Transforming Speech Into Impactful Video
Voice-to-video converts spoken words into dynamic video content. Learn how it works, top use cases, key features, challenges, and smart alternatives.
Devdeep
Author
Voice-to-Video: Transforming Speech Into Impactful Video

Most American companies are searching for smarter ways to turn spoken ideas into visual stories. As demand for video content rises, many discover that voice-to-video technology reduces production time by over 60 percent. This innovation matters because audiences now expect engaging, instantly shareable media on every platform. Here, you will learn how American professionals use voice-to-video tools to streamline workflows and spark creativity across every industry.
Table of Contents
Key Takeaways
| Point | Details |
|---|---|
| Voice-to-Video Technology | This technology converts spoken audio into visual content using advanced AI, enhancing multimedia production. |
| Key Applications | Various sectors such as education and marketing leverage voice-to-video for creating engaging video communications. |
| Challenges | Technical issues like high computational demands and ethical concerns regarding deepfakes present barriers to adoption. |
| Best Practices | Optimize audio quality and explore different platforms to find the best tools for specific content creation needs. |
Defining Voice-to-Video Technology and Its Purpose
- Defining Voice-to-Video Technology and Its Purpose
- How Voice-to-Video Conversion Works
- Key Features and Tools in Modern Solutions
- Popular Use Cases for Voice-to-Video Content
- Challenges, Limitations, and Best Alternatives
Voice-to-video technology represents a groundbreaking digital transformation where spoken audio gets converted into dynamic visual content through advanced artificial intelligence. This innovative process transforms speech inputs into corresponding multimedia outputs, enabling creators to generate compelling videos directly from vocal recordings.
At its core, voice-to-video technology works by analyzing audio signals and intelligently mapping them to visual representations. Modern generative AI algorithms break down vocal characteristics like tone, rhythm, and emotional context, then synchronize these elements with generated imagery. Sophisticated speech-to-video generation techniques allow for nuanced translations of audio into contextually relevant visual narratives.
The practical applications of this technology span multiple industries. Professionals in customer service can create personalized video communications, educators can develop engaging instructional content, and content creators can produce multilingual video presentations without extensive editing. By automating visual storytelling, voice-to-video tools dramatically reduce production time and technical barriers.
Pro Tip: Start with clear, well-enunciated audio recordings when using voice-to-video technology to ensure the most accurate and compelling visual translations.
How Voice-to-Video Conversion Works
Voice-to-video conversion represents a sophisticated technological process that transforms audio input into dynamic visual content through intricate artificial intelligence algorithms. Cross-modal speech processing frameworks leverage advanced machine learning techniques to analyze and translate vocal characteristics into corresponding visual representations.

The conversion process involves several critical stages of computational analysis. Initially, generative AI algorithms deconstruct audio signals, extracting nuanced elements like emotional tone, speech patterns, and contextual information. Machine learning models then map these audio features to potential visual representations, using neural networks trained on extensive multimedia datasets. Advanced text-to-speech models with visual conditioning enable precise synchronization between spoken words and generated visual content, ensuring realistic and coherent video output.
Technical mechanisms underlying voice-to-video conversion include spectral analysis, semantic mapping, and generative adversarial networks. These systems analyze vocal input across multiple dimensions: linguistic content, emotional context, speech rhythm, and speaker identity. Modern video creation tools integrate these complex algorithmic processes to produce seamless, contextually appropriate visual narratives that capture the essence of the original audio input.
Pro Tip: Optimize your audio input by using high-quality microphones and recording in quiet environments to ensure the most accurate voice-to-video conversion results.
Key Features and Tools in Modern Solutions
Modern voice-to-video technologies are revolutionizing digital communication through sophisticated artificial intelligence tools that transform spoken content into dynamic visual narratives. Advanced multi-speaker video synthesis systems enable unprecedented flexibility in generating high-quality, contextually rich video content from audio inputs.
Key features of cutting-edge voice-to-video solutions include intelligent audio analysis, semantic mapping, and generative visual rendering. These tools incorporate complex machine learning algorithms that can extract emotional nuances, linguistic context, and speaker identity from raw audio signals. Contemporary platforms optimize video communication methods by integrating natural language processing, computer vision, and deep learning techniques to produce seamless, engaging multimedia content.
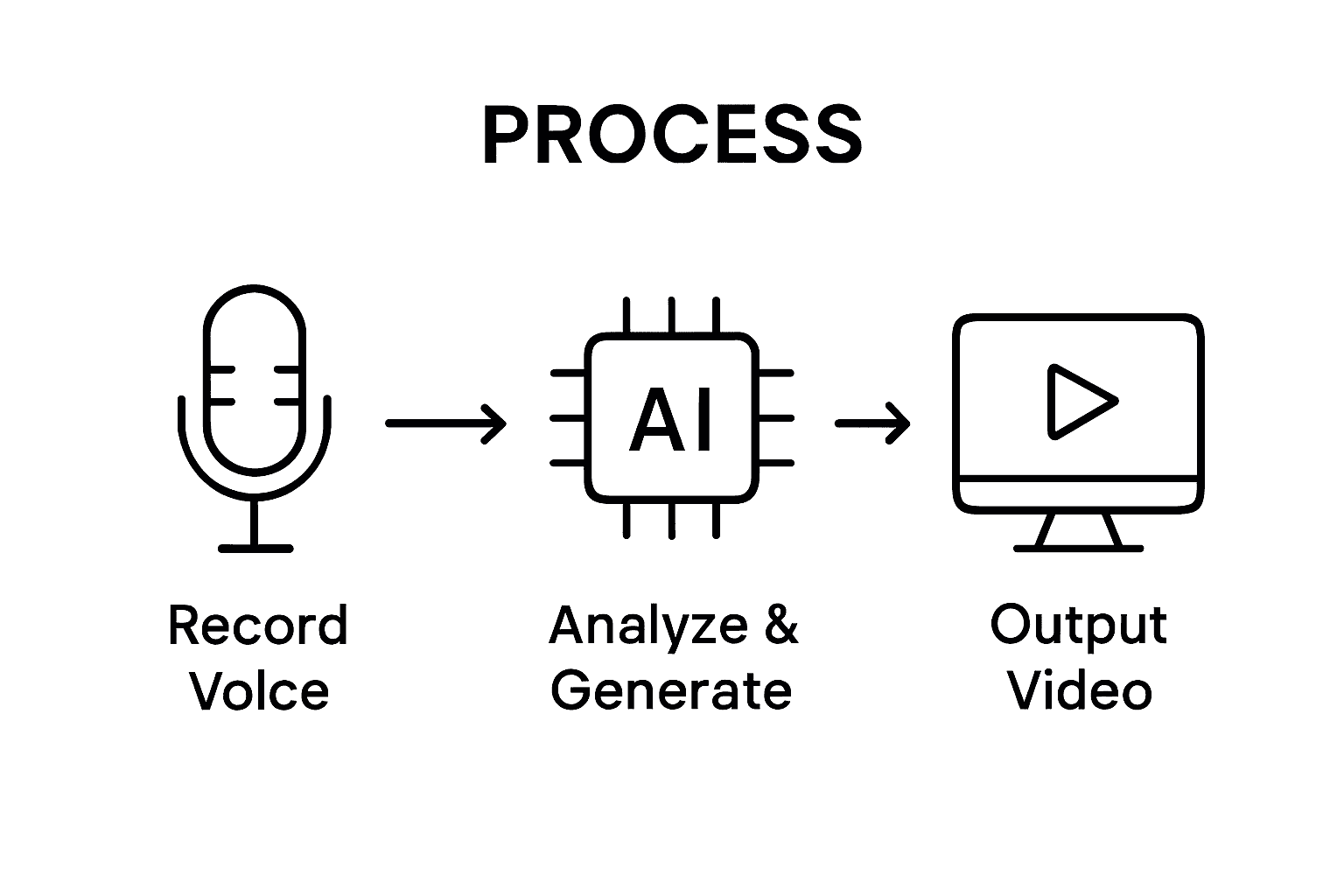
The technological landscape of voice-to-video solutions encompasses several critical components. Artificial intelligence frameworks now support features like emotional tone preservation, lip-sync accuracy, and multilingual content generation. Professional-grade tools leverage neural networks trained on extensive multimedia datasets to ensure that generated videos maintain the authenticity and intent of the original audio input. These advanced async video collaboration tools are transforming how professionals communicate, create content, and share information across global platforms.
Pro Tip: Research and compare multiple voice-to-video platforms to identify tools that best match your specific content creation and communication requirements.
Popular Use Cases for Voice-to-Video Content
Voice-to-video technology has rapidly expanded across multiple professional and creative domains, transforming how organizations communicate and create content. Advanced voice-to-video applications demonstrate significant potential in sectors ranging from education and marketing to corporate training and customer engagement.
Educational institutions are leveraging this technology to revolutionize learning experiences. Instructors can now generate dynamic instructional videos by simply recording audio, allowing complex concepts to be explained through visually engaging content. Product teams explore innovative video communication strategies that enable more interactive and personalized learning materials, breaking traditional boundaries of classroom instruction.
Business communication strategies have been dramatically transformed by voice-to-video technologies. Marketing departments create personalized video advertisements, sales teams develop engaging product demonstrations, and customer support representatives generate more empathetic and clear communication materials. Startup founders, freelancers, and remote teams can now produce professional-quality content without extensive video production skills, democratizing multimedia communication.
Pro Tip: Start with clear, concise audio scripts and practice recording in a quiet environment to maximize the quality of your voice-to-video content.
Here's a comparison of major business benefits across different voice-to-video technology use cases:
| Use Case | Main Benefit | Typical Output | Business Impact |
|---|---|---|---|
| Education | Enhanced engagement | Visual lessons | Improved learning retention |
| Marketing | Personalized messaging | Dynamic video ads | Higher audience conversion |
| Customer Support | Empathetic communication | Support videos | Increased customer loyalty |
| Remote Work | Efficient collaboration | Team updates | Streamlined project workflows |
Challenges, Limitations, and Best Alternatives
Voice-to-video technology, while promising, confronts significant technical and ethical challenges that impact its widespread adoption. Text-to-video models encounter substantial computational demands that create barriers for smaller organizations and individual creators seeking to leverage these innovative tools.
Technical limitations primarily stem from the immense complexity of generating contextually accurate and visually coherent video content from audio inputs. Machine learning models require extensive training datasets and sophisticated neural networks to produce realistic results. These constraints mean that current voice-to-video solutions often struggle with nuanced emotional translation, maintaining consistent visual narratives, and preserving speaker authenticity. Async video collaboration platforms are continuously working to address these technical challenges by improving AI algorithms and expanding training datasets.
Ethical considerations represent another critical challenge in voice-to-video technology. Audio deepfake technologies raise significant privacy and misinformation concerns, prompting discussions about potential misuse and the need for robust regulatory frameworks. The potential for creating synthetic media that could manipulate perceptions or impersonate individuals demands careful technological governance and responsible development practices.
Below is a summary of key technical and ethical challenges facing voice-to-video technology:
| Challenge Type | Specific Issue | Potential Impact |
|---|---|---|
| Technical | High computational demands | Limits widespread adoption |
| Technical | Inconsistent emotional rendering | Reduces content authenticity |
| Ethical | Audio deepfakes risk | Misinformation concerns |
| Ethical | Privacy in synthetic content | Regulatory implications |
Pro Tip: Always verify the credibility of voice-to-video platforms by examining their data protection policies, understanding their AI generation methods, and reviewing independent third-party assessments of their technological capabilities.
Transform Your Speech Into Engaging Videos with Boom
Voice-to-video technology is transforming how we create and share content by turning spoken words into compelling visual stories. Yet challenges like complex AI processes, time-consuming edits, and maintaining authentic communication remain significant hurdles for individuals and teams eager to leverage this innovation. If you want to overcome these pain points and harness voice-to-video with ease, Boom offers a powerful AI-driven solution built precisely for your needs.
Boom's voice-to-video recording feature lets you say what you mean and instantly produce polished videos that combine voice, visuals, and timing without manual editing. With additional tools like auto-scripting, professional AI voiceover and multilingual dubbing, and async-first design, Boom eliminates scheduling headaches and saves you valuable time in every video you make. These features ensure your videos deliver emotional nuance and clear communication aligned with your goals, making Boom the ideal platform for freelancers, remote teams, marketers, and content creators embracing this new wave of digital storytelling.
Ready to transform your voice into impactful video content today Visit Boom's landing page to experience an AI-powered async video tool designed to free up your schedule and amplify your message. Every moment saved is a moment earned so explore how Boom helps you create, speak, and share compelling videos without meetings.
Start your free journey now to harness the future of video communication with Boom's innovative voice-to-video capabilities.
Frequently Asked Questions
What is voice-to-video technology?
Voice-to-video technology converts spoken audio into dynamic visual content using artificial intelligence, allowing creators to generate videos directly from vocal recordings.
How does voice-to-video conversion work?
The process involves analyzing audio signals to extract features like tone and emotional context, which are then mapped to relevant visual representations through advanced machine learning algorithms.
What are the main benefits of using voice-to-video technology?
Key benefits include enhanced communication effectiveness, reduced production time, and the ability for users to create engaging multimedia content without extensive video editing skills.
What are the challenges associated with voice-to-video technology?
Challenges include high computational demands for generating accurate content, potential inconsistencies in emotional rendering, and ethical issues related to privacy and misinformation.
Recommended
About the Author
Devdeep
Senior Software Engineer.